# cloud-demo
**Repository Path**: sunwdong/cloud-demo
## Basic Information
- **Project Name**: cloud-demo
- **Description**: 学习记录
【尚硅谷2025最新SpringCloud教程,springcloud从入门到大牛 | 7小时速通】 https://www.bilibili.com/video/BV1UJc2ezEFU/
文档:https://www.yuque.com/leifengyang/sutong/oz4gbyh5maa0rmxu
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 6
- **Forks**: 1
- **Created**: 2025-01-23
- **Last Updated**: 2025-11-13
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
[尚硅谷SpringCloud 7小时快速通关.视频](https://www.bilibili.com/video/BV1UJc2ezEFU/?vd_source=90e069d391ef8d8b231878ddf5931333)
[SpringCloud-快速通关.文档](https://www.yuque.com/leifengyang/sutong/oz4gbyh5maa0rmxu)
## nacos
### 注册中心
### 配置中心
1. 配置文件: SpringBoot V2.4后增加配置项, nacos为统一口径, 须显示写出需要引入的配置dataId和group(
可选,不填为DEFAULT_GROUP)
```yaml
spring:
application:
name: @artifactId@
cloud:
nacos:
server-addr: 127.0.0.1:8848
config:
server-addr: ${spring.cloud.nacos.server-addr}
#group: DEFAULT_GROUP
namespace: ${spring.profiles.active}
file-extension: yaml
import-check:
enabled: false # 禁用启动时导入检查
config:
import:
- nacos:${spring.application.name}-${spring.profiles.active}?group=DEFAULT_GROUP
- nacos:${spring.application.name}-hello?group=DEFAULT_GROUP
```
2. 使用
1. @Value + @RefreshScope 注解
2. @ConfigurationProperties(prefix=xxxx) 注解: 集中配置项,减少代码量,同时也具备自动刷新配置
3. 监听变化
从容器中获取NacosConfigManager, 使用getConfigService()#addListener()添加Listener
### 拓展
1. 引入其他yaml配置文件
```yaml
spring:
profiles:
include:
- feign # 引入同级目录下名称为application-feign.yml的配置文件
- sentinel # 引入同级目录下名称为application-sentinel.yml的配置文件
```
2. SpringCloud中支持多环境配置
* 数据隔离-动态切换环境:
在一个配置文件中为不同环境自定义配置项,只有`spring.config.activate.on-profile`与`spring.profiles.active`相同对应部分才会生效
```yaml
---
spring:
config:
activate:
on-profile: dev
import:
- nacos:${spring.application.name}-${spring.profiles.active}?group=DEFAULT_GROUP
- nacos:dev?group=order
---
spring:
config:
activate:
on-profile: test
import:
- nacos:${spring.application.name}-${spring.profiles.active}?group=DEFAULT_GROUP
---
spring:
config:
activate:
on-profile: prod
import:
- nacos:${spring.application.name}-${spring.profiles.active}?group=DEFAULT_GROUP
- nacos:prod?group=order
```
## openFeign
1. 超时时间
```properties
spring.cloud.openfeign.client.config.default.connect-timeout=1000
spring.cloud.openfeign.client.config.default.read-timeout=2000
spring.cloud.openfeign.client.config.feign的名称.connect-timeout=1000
spring.cloud.openfeign.client.config.feign的名称.read-timeout=2
```
2. 日志
1. 配置文件
```properties
spring.cloud.openfeign.client.config.default.logger-level=full
spring.cloud.openfeign.client.config.feign的名称.logger-level=full
```
2. 容器注入bean, 会自动生效
```java
@Bean
public Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
```
3. 重试:仅在服务调用失败 或 响应头中包含Retry-After时才会重试
1. 配置文件
```properties
spring.cloud.openfeign.client.config.default.retryer=feign.Retryer.Default
spring.cloud.openfeign.client.config.feign的名称.retryer=feign.Retryer.Default
```
2. 容器注入bean
```java
@Bean
public Retryer retryer() {
return new Retryer.Default();
}
```
4. interceptor
1. 编码
1. request: 实现feign.RequestInterceptor
2. response: 实现feign.ResponseInterceptor
2. 生效
1. 容器注入bean, 会自动生效
2. 配置文件
```properties
spring.cloud.openfeign.client.config.default.requestInterceptors=tech.cyhk.cloud.demo.order.interceptor.FeignRequestTokenInterceptor,xxxxx,yyyyy
```
5. fallback: 当服务不可用或抛出异常时,会调用fallback方法 需要结合其他熔断组件
## sentinel
### 如何使用
> 使用wiki:https://github.com/alibaba/Sentinel/wiki
1. web层实现了intercept,如果容器中没有BlockExceptionHandler实例,就用DefaultBlockExceptionHandler来处理BlockException
2. 对于@SentinelResource注解的资源,会依次检查blockHandler、fallback、defaultFallback属性找到对应的处理方法,都没有则抛出异常
3.
对于OpenFeign调用,会用SentinelFeign.Builder代替Feign.Builder作为FeignClient的代理构建器,也就创建SentinelInvocationHandler的代理对象,使用fallback来处理
4. Spuh就是编码式的方式对进行流控
### [规则管理及推送](https://github.com/alibaba/Sentinel/wiki/%E5%9C%A8%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E4%B8%AD%E4%BD%BF%E7%94%A8-Sentinel)
一般来说,规则的推送有下面三种模式:
1. 原始模式:
如果不做任何修改,Dashboard 的推送规则方式是通过 API 将规则推送至客户端并直接更新到内存中:
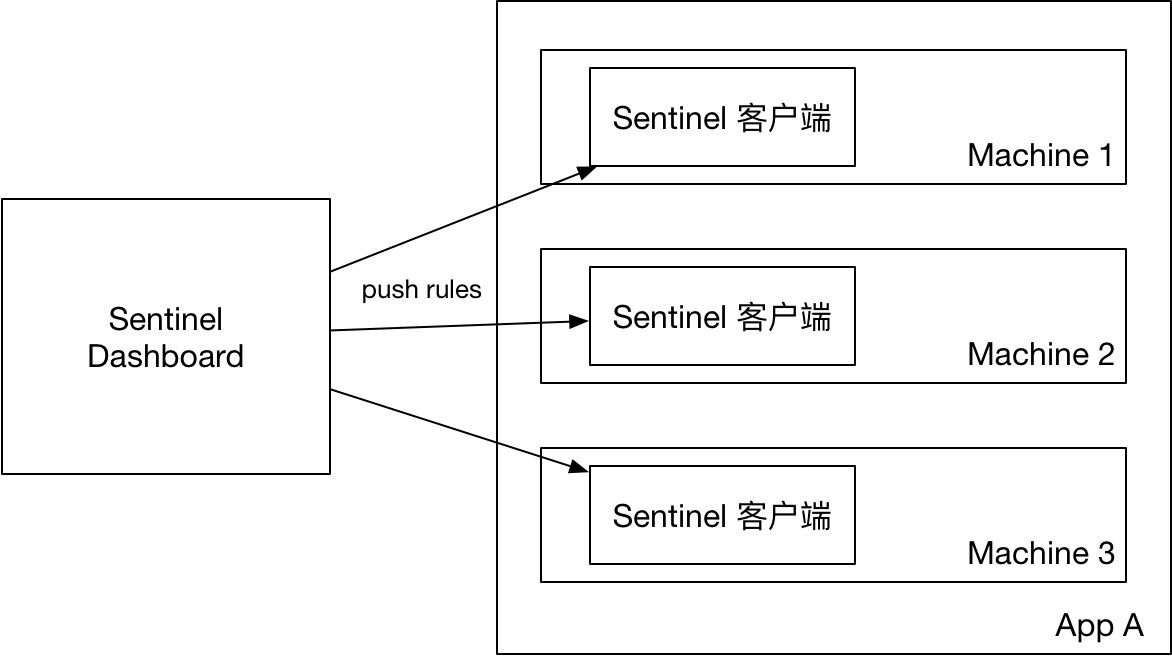
扩展写数据源(WritableDataSource), 客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件等。
数据源(如本地文件、RDBMS 等)一般是可写入的。使用时需要在客户端注册数据源:将对应的读数据源注册至对应的
RuleManager,将写数据源注册至 transport 的 WritableDataSourceRegistry 中。以本地文件数据源为例:
```java
public class FileDataSourceInit implements InitFunc {
@Override
public void init() throws Exception {
String flowRulePath = "xxx";
ReadableDataSource> ds = new FileRefreshableDataSource<>(
flowRulePath, source -> JSON.parseObject(source, new TypeReference>() {})
);
// 将可读数据源注册至 FlowRuleManager.
FlowRuleManager.register2Property(ds.getProperty());
WritableDataSource> wds = new FileWritableDataSource<>(flowRulePath, this::encodeJson);
// 将可写数据源注册至 transport 模块的 WritableDataSourceRegistry 中.
// 这样收到控制台推送的规则时,Sentinel 会先更新到内存,然后将规则写入到文件中.
WritableDataSourceRegistry.registerFlowDataSource(wds);
}
private String encodeJson(T t) {
return JSON.toJSONString(t);
}
}
```
本地文件数据源会定时轮询文件的变更,读取规则。这样我们既可以在应用本地直接修改文件来更新规则,也可以通过 Sentinel
控制台推送规则。以本地文件数据源为例,推送过程如下图所示:
3. push模式:
生产环境下一般更常用的是 push 模式的数据源。对于 push 模式的数据源,如远程配置中心(ZooKeeper, Nacos, Apollo等等),推送的操作不应由
Sentinel 客户端进行,而应该经控制台统一进行管理,直接进行推送,数据源仅负责获取配置中心推送的配置并更新到本地。因此推送规则正确做法应该是
配置中心控制台/Sentinel 控制台 → 配置中心 → Sentinel 数据源 → Sentinel,而不是经 Sentinel 数据源推送至配置中心。这样的流程就非常清晰了:
[动态规则扩展](https://sentinelguard.io/zh-cn/docs/dynamic-rule-configuration.html)
### 规则
#### [流量控制](https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6)
1. 阈值类型
* QPS: 统计每秒请求数
* 并发线程数: 统计并发线程数
并发数控制用于保护业务线程池不被慢调用耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的
overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel
并发控制不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目(正在执行的调用数目),如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。并发数控制通常在调用端进行配置。
例子参见:[ThreadDemo](https://github.com/alibaba/Sentinel/blob/master/sentinel-demo/sentinel-demo-basic/src/main/java/com/alibaba/csp/sentinel/demo/flow/FlowThreadDemo.java)
2. 是否集群-集群阈值模式
* 单机均摊:
* 总体阈值:
3. 流控模式
1. 直接:
2. 关联:
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。
比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身
带来的开销会降低整体的吞吐量。
可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和 write_db 这两个资源分别代表数据
库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 流控模式`FlowRule.strategy` 为 关联
`RuleConstant.RELATE` 同时设置
关联资源 `FlowRule.ref_identity` 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
3. 链路:
底层`NodeSelectorSlot`中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为
machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
```
```
machine-root
/ \
/ \
Entrance1 Entrance2
\ /
\ /
DefaultNode(nodeA)
```
上图中来自入口 `Entrance1` 和 `Entrance2` 的请求都调用到了资源 `NodeA`,Sentinel 允许只根据某个入口的统计信息对资源限流。
比如我们可以设置 流控模式`FlowRule.strategy` 为 链路`RuleConstant.CHAIN`,同时设置 入口资源`FlowRule.ref_identity` 为
`Entrance1` 来表示只有从入口 `Entrance1` 的调用才会记录到 NodeA 的限流统计当中,而对来自 `Entrance2` 的调用漠不关心。
调用链的入口是通过 API 方法 `ContextUtil.enter(name)` 定义的。
```
4. 流控效果
> 注意:**_若使用除了直接拒绝之外的流量控制效果,则调用关系限流策略(strategy)会被忽略。_**
1. 快速失败:
`RuleConstant.CONTROL_BEHAVIOR_DEFAULT`
默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。具体的例子参见 [FlowQpsDemo](https://github.com/alibaba/Sentinel/blob/master/sentinel-demo/sentinel-demo-basic/src/main/java/com/alibaba/csp/sentinel/demo/flow/FlowQpsDemo.java)。
2. warm up:
`RuleConstant.CONTROL_BEHAVIOR_WARM_UP`
即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"
冷启动"
,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。详细文档可以参考[流量控制 - Warm Up 文档](https://github.com/alibaba/Sentinel/wiki/%E9%99%90%E6%B5%81---%E5%86%B7%E5%90%AF%E5%8A%A8)
,具体的例子可以参见 [WarmUpFlowDemo](https://github.com/alibaba/Sentinel/blob/master/sentinel-demo/sentinel-demo-basic/src/main/java/com/alibaba/csp/sentinel/demo/flow/WarmUpFlowDemo.java)。
通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:
3. 排队等待:
`RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER` 方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
详细文档可以参考 [流量控制 - 匀速器模式](https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6-%E5%8C%80%E9%80%9F%E6%8E%92%E9%98%9F%E6%A8%A1%E5%BC%8F)
,具体的例子可以参见 [PaceFlowDemo](https://github.com/alibaba/Sentinel/blob/master/sentinel-demo/sentinel-demo-basic/src/main/java/com/alibaba/csp/sentinel/demo/flow/PaceFlowDemo.java)。
该方式的作用如下图所示:
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
> 注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
#### [熔断降级 degrade](https://github.com/alibaba/Sentinel/wiki/%E7%86%94%E6%96%AD%E9%99%8D%E7%BA%A7)
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的
某一环不稳定,就可能会层层级联,最终导致整个链路都不可用。因此我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定
因素导致整体的雪崩。熔断降级作为保护自身的手段,**通常在客户端(调用端)进行配置**。
1. 目的
* 切断不稳定调用
* 快速返回不积压
* 避免雪崩
2. 状态
1. 半开状态:
2. 闭合状态:
3. 断开状态:
2. 策略
1. 慢调用比例 (`SLOW_REQUEST_RATIO`):
选择以慢调用比例作为阈值,需要设置允许的慢调用 `RT`(即最大的响应时间),请求的响应时间大于该值则统 计为慢调用。当单位统计时长(
`statIntervalMs`)
内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态
(`HALF-OPEN` 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 `RT` 则会再次被熔断。
2. 异常比例 (ERROR_RATIO):
当单位统计时长(`statIntervalMs`)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔
断时长后熔断器会进入探测恢复状态(`HALF-OPEN` 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值
范围是 [0.0, 1.0],代表 0% - 100%。
3. 异常数 (`ERROR_COUNT`):
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(`HALF-OPEN`
状态),若接下来的一个请求成功
完成(没有错误)则结束熔断,否则会再次被熔断。
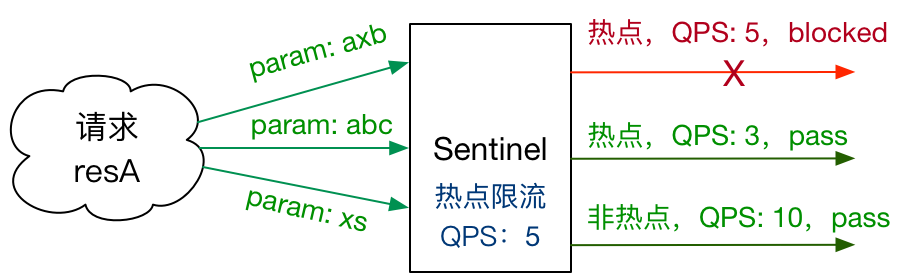
#### [热点参数限流](https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81)
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。*
*热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。**